Sep 30, 2025
Retrieval-Augmented Generation (RAG) is one of the most powerful ways to combine knowledge retrieval with large language models (LLMs). Instead of relying only on what the model was trained on, RAG allows you to connect your model to external knowledge bases such as documents, PDFs, databases, APIs and more. In this way, you can get fresher, more accurate, and more transparent answers.
In this article, we are going to explore advanced RAG techniques beyond the basic RAG pipelines and show you how these techniques translate directly into Stack AI workflows, without the need for complex infrastructure.
Let 's get into it!
The evolution from basic RAG pipelines to advanced architectures
Basic RAG pipelines follow a simple process:
Retrieve: find documents that match the query
Augment: feed context into the LLM
Generate: return an answer
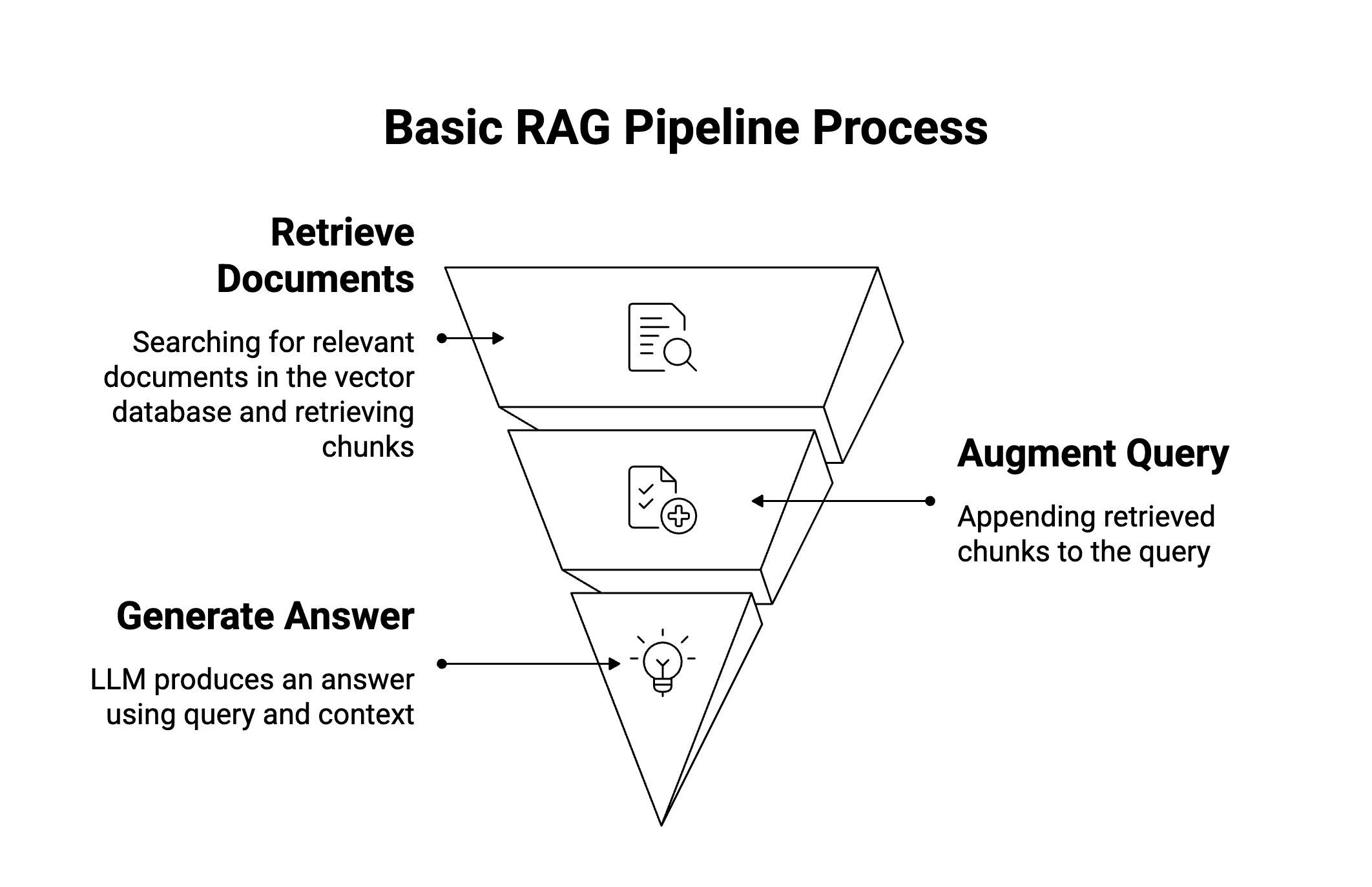
To make this work, documents are usually broken into chunks (small text sections) so the model can process them more easily. The model then uses the most relevant chunks as context to generate its answer. Ideally, the answer is grounded — meaning it comes directly from the retrieved documents.
This basic setup is powerful, but it also has limitations. Sometimes the wrong chunks are chosen, and therefore, you might get irrelevant answers. Other times, the model might miss important context or generate a response that isn’t properly grounded in the documents.
In order to work around this, advanced techniques tackle these issues with smarter chunking, better retrieval strategies, reranking, filtering…
But the challenge with advanced RAG is that, while the techniques are very powerful, they can also be complex to build on your own. With Stack AI, you get access to some of these techniques straight out of the box, with settings you can adjust in just a few clicks.
Eight Advanced RAG Techniques
Let’s look at some advanced RAG techniques and how you can use them in StackAI.
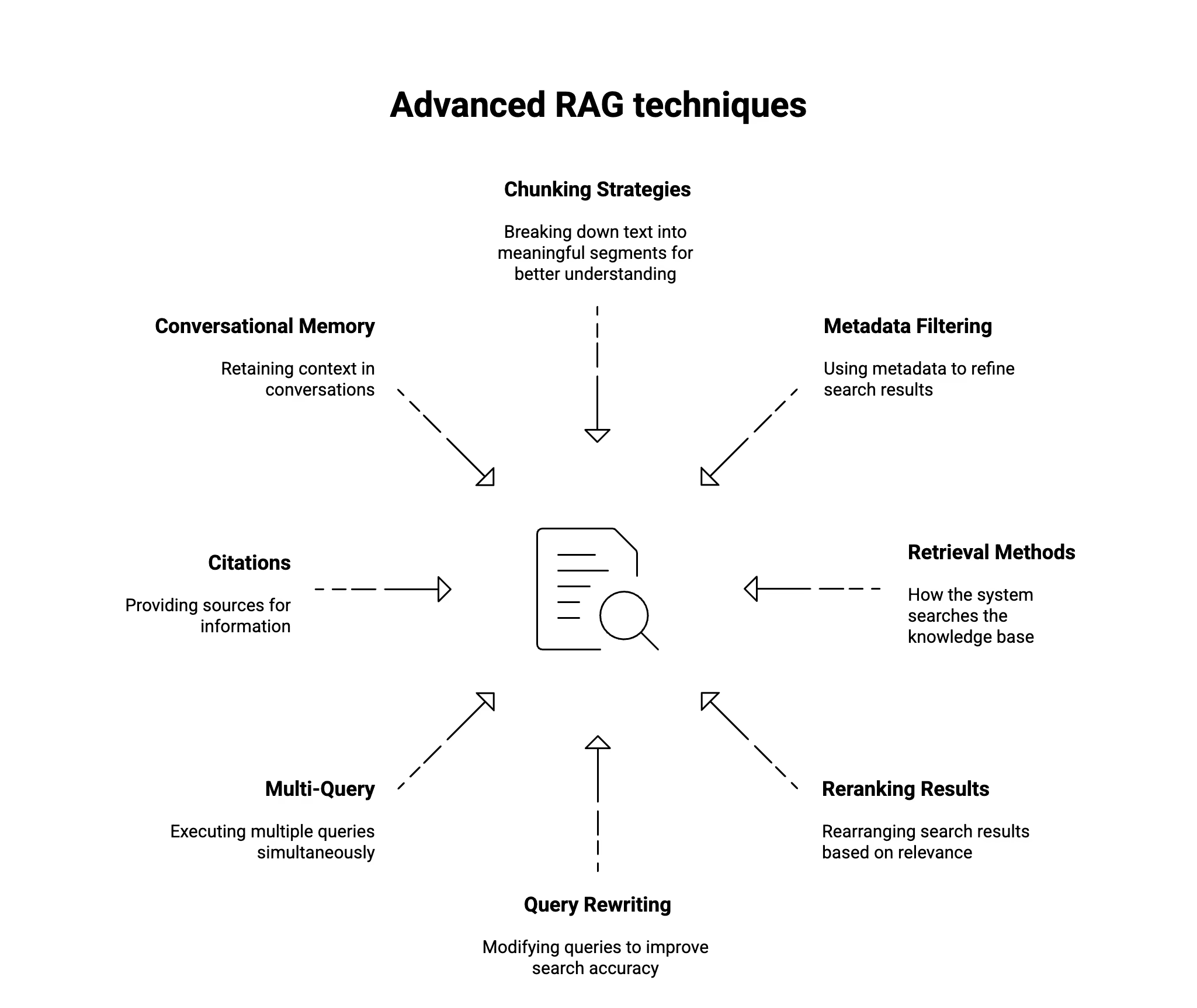
Chunking Strategies
One of the most overlooked but critical design choices in any RAG pipeline is how you split documents into chunks. The chunking strategy directly affects what the retriever can find and what the LLM can understand. If chunks are too large, you risk burying small but important details inside a block of irrelevant text, so the system may not retrieve them at all. If chunks are too small, the model only sees fragments without enough surrounding context, which can lead to shallow or incomplete answers.
To strike the right balance, advanced RAG systems use smarter chunking strategies.
Semantic chunking: Instead of chopping text by a fixed character count, the system divides it by meaning. That might mean breaking at paragraph boundaries, section headers, or natural topic shifts, so each chunk represents a self-contained idea. This way, the retriever surfaces meaningful units rather than random slices of text.
Overlapping: Even with semantic splits, sometimes important information falls right at the edge of a chunk. Overlapping solves this by adding a small buffer of repeated text between consecutive chunks. For example, the last few sentences of one chunk might also appear at the start of the next, making sure nothing essential gets cut off.
Dynamic chunk sizing: Not all documents are the same. A technical manual full of dense instructions might work best with shorter chunks so each is focused and precise. A narrative report or FAQ, on the other hand, can tolerate longer chunks that capture broader context. Dynamic chunking adjusts the size depending on the type and density of the content, giving the model the right amount of context for the task.

These strategies make retrieval much more robust and the LLM’s responses more accurate. But they also add complexity: deciding where to split, how much overlap to use, and when to adjust chunk size requires careful design — and sometimes even trial and error on the specific dataset.
With Stack AI, you don’t need to engineer these algorithms yourself. The platform gives you simple, practical controls to manage how text is sliced and retrieved. Instead of coding custom preprocessing, you can decide how much text is treated as a chunk, how many chunks are retrieved, and how much content is passed into the LLM’s context window — capturing many of the same benefits in a much simpler way.
When choosing Output Format: Chunks in your knowledge base node, you tell the system to break documents into smaller sections rather than treating them as a whole. With the Max Characters slider, you can adjust the amount of text passed into the LLM’s context window, which is a practical way to manage granularity and cost. And the Max Chunks setting defines how many chunks are retrieved at once, keeping the results focused.

Metadata Filtering
Another challenge in retrieval is precision. Sometimes the system finds information that is technically related to the query but comes from the wrong type of document. For example, if someone asks about “safety rules,” the model might pull text from a marketing brochure instead of the official safety policy.
Advanced RAG techniques solve this with metadata filtering. When documents are tagged with properties like type, source, date, or category, the retriever can filter results to only include the most relevant group. This makes the system smarter by narrowing its search space.
Think of metadata as “labels” or “tags” attached to documents. Instead of just storing the raw text, you also store information like:
Type: is this a PDF, an FAQ, a forum post, or a policy document?
Source: did it come from an internal knowledge base, a website, or a customer email?
Date: when was it created or last updated?
Category/Topic: does it relate to billing, technical support, or product features?

When a user asks a question, the retriever doesn’t just look at semantic similarity between the query and text. It can also filter results to only include documents matching certain metadata. For example:
If the question is “What’s the latest refund policy?”, the system can filter by date to only include the newest version of the policy.
If the query is about “technical setup,” the system can filter by category so it doesn’t pull in irrelevant billing documents.
If the user specifies “from the handbook,” the retriever can filter by source and ignore everything else.
When you narrow the search space with metadata filters, the retriever isn’t overwhelmed by noise, and the LLM only sees documents that are more likely to answer the question accurately.
Stack AI makes this easy through the Metadata Filter Strategy setting. Here, you can decide whether to apply no filter, a strict filter that only allows exact matches, or a loose filter that applies metadata more flexibly. This gives you control over how tightly retrieval follows your document structure.

Retrieval Methods
One of the most fundamental questions in a RAG pipeline is how should the system actually search the knowledge base. The quality of retrieval determines the quality of the final answer, so this step really makes or breaks the system.
Traditionally, retrieval was done through keyword search. This is the classic method used in search engines: the system looks for documents that contain the same words as the query. If you type “refund policy”, it finds all passages that include those exact terms. This works well for simple lookups, but it has a major limitation — if the user phrases their query differently, relevant results can be missed. For example, “money back rules” might not match “refund policy,” even though they mean the same thing.
To overcome this, advanced RAG pipelines often use semantic search. Instead of comparing words directly, both queries and documents are converted into embeddings, which are basically numerical vectors that capture their meaning in high-dimensional space. Because embeddings focus on semantics rather than exact wording, the system can recognize that “alcohol rules” and “no drinks are allowed” refer to the same concept, even though the words don’t overlap.
The most effective approach in practice is often hybrid search, which combines the best of both worlds. Keyword search provides precision by catching exact matches when they matter, like product names, codes, or legal terms, while semantic search adds flexibility, making sure that paraphrased or loosely related queries still find the right documents.

Hybrid search greatly improves both recall and accuracy.

Stack AI makes these strategies available out of the box. In the Query Strategy setting, you can choose between Keyword, Semantic, or Hybrid search, depending on your needs.
Reranking Retrieved Results
Even when retrieval works, not every chunk the system finds is equally useful. Some may only mention the keyword in passing, while others go into detail. Without a way to prioritize, the underlying model might base its answer on the wrong piece of text.
A basic retriever might bring back the top 5 chunks that look similar to the query, but they might not be ordered by relevance. Reranking solves this issue.
The idea is straightforward: after the initial retrieval step, the system takes the candidate documents and reorders them by relevance before handing them to the model. Instead of blindly trusting the retriever’s similarity scores, reranking applies a second, more sophisticated check.

At the simplest level, reranking might use lightweight heuristics, like giving higher weight to documents that contain exact keyword matches. But the more advanced approach uses cross-encoder models. Unlike the retriever (a bi-encoder) that encodes query and documents separately, a cross-encoder looks at the query and a candidate document together in the same model pass. This allows it to reason about fine-grained relationships — for example, whether a policy document actually answers the user’s question, or whether the overlap is just superficial.
Assigning a relevance score to each query–document pair, allows the cross-encoder to reshuffle the ranking so the most promising results rise to the top. The model then sees fewer but higher-quality documents, which reduces hallucinations, improves accuracy, and makes responses more concise.
Stack AI abstracts this process with a single toggle. When you enable rerank, you let the system reorder the retrieved chunks so that the most relevant ones are placed at the top. This increases the chance that the LLM bases its response on the right information.

Query Rewriting and Expansion
Sometimes the limitation in RAG isn’t with the documents at all — it’s with the query. Users don’t always phrase their questions in the same way that information is stored in the knowledge base. If the retriever only looks for a literal match, it might miss the right documents completely. A technique to approach this is query transformation.
Instead of sending the raw user query straight to the retriever, the system rewrites or expands it into different variations that capture the same intent so the retriever has a better chance of finding relevant matches.
There are several strategies for this. One is multi-query generation, where the model creates a handful of alternative phrasings — for example, turning “How do I get a refund?” into “What’s the refund process?”, “Can I return my purchase?”, and “Steps to claim money back.” Each of these is then run through the retriever, and the combined results cover more ground.
Another clever approach is HyDE (Hypothetical Document Embeddings). Instead of just rewriting the question, the model actually generates a short, “fake” answer that looks like the kind of document that might exist. That hypothetical document is then embedded and used to search the vector database. Because embeddings capture meaning rather than exact words, this trick often pulls in highly relevant passages that a plain query might have missed.

The benefit of query transformation is that it makes the retrieval step more robust to user phrasing, synonyms, and ambiguity. In practice, this means the model has access to a richer, more accurate context set — which directly translates into better answers.

In Stack AI, this process is simplified with a toggle. Under Query Transformation, you can activate transformations that automatically reformulate queries. Options like Keywords and HyDE are available.
Multi-Query and Advanced Q&A
In the real world, user queries are rarely neat one-liners. People often ask compound questions or pose challenges that require reasoning across different pieces of information. For example, someone might ask, “What’s the refund policy for flights booked last year, and how does it differ from the current one?” That isn’t just one question — it’s really two bundled together.
If the system treats this as a single query and runs it through retrieval, it might only surface part of the needed context. The result can be an answer that feels incomplete or even misleading.
To tackle this, advanced RAG pipelines use multi-query expansion. The idea is to break down a complex query into smaller, more manageable sub-questions. Each sub-question is sent to the retriever, which gathers targeted documents for that piece. Once the results are collected, the system can merge them, compare them, or summarize across sources to deliver a comprehensive answer.
Multi-document reasoning is another advanced technique. Instead of just looking at one document in isolation, the model learns to weave together evidence from multiple places. For instance, it might pull policy details from one source, historical terms from another, and then contrast them directly in the final response.

The benefit is that the model doesn’t just answer the first part of a user’s question — it addresses the whole thing, capturing nuance, differences, and relationships across documents.
Stack AI makes this simple with two settings:
Answer Multiple Questions allows the system to handle several questions in parallel. So if a user asks “What time do the gates open and where can I park?”, Stack AI retrieves chunks for both the opening hours and parking guide and merges them into one clear answer.
Advanced Q&A goes a step further. It lets the system tackle questions that require comparison or summarization across documents. For example, if a user asks “What’s the difference between the general admission and VIP ticket policies?”, Stack AI can pull from multiple PDFs, compare the relevant sections, and return a concise explanation.
With these techniques, your system isn’t limited to one-question-at-a-time responses — it can deliver nuanced, multi-document answers that feel far closer to real human interaction.
Citations and Grounded Responses
One of the biggest hurdles in making AI systems truly useful is trust. Users don’t just want an answer — they want to know why that answer is correct and where it came from. A plain LLM can generate something that sounds perfectly reasonable, but unless it’s grounded in the actual documents, there’s no guarantee it’s true (and sometimes not even that!). This is where citations become an essential advanced RAG technique.
Whenever the system generates an answer, it also attaches links or references to the specific documents that supported it. Instead of just reading, “You are eligible for a refund within 14 days,” the user also sees something like, “(Source: Refund Policy, Section 2.1).”

This does two things. First, it proves reliability by showing that the AI didn’t just “make it up” — the statement is directly backed by evidence. Second, it empowers the user to dive deeper if they want, by checking the original source for context.
Technically, implementing citations usually involves tracking which chunks of text were retrieved and passed into the LLM, then asking the model to include references to those chunks in its output. Some advanced setups even highlight the exact sentence or passage that the answer came from.
When you ground responses in sources, citations transform the model from a “black box that sounds smart” into something closer to a trustworthy assistant — one that can explain itself and give the user confidence in its answers.
Stack AI builds this in as well. With citation settings enabled, each answer can include references to the exact chunk or document it was retrieved from.
Conversational Memory
Real conversations are rarely one-off exchanges. People ask follow-up questions, refine their requests, or add new details as the dialogue unfolds. If an AI system treats every query in isolation, it quickly becomes frustrating — the user has to repeat themselves over and over, and the natural flow of conversation breaks down.
Conversational memory is the solution. Instead of discarding context after each turn, the system keeps track of what’s already been said and uses that history as part of the retrieval process for the next query. For example, if a user first asks, “What’s the refund policy for business class flights?” and then follows up with, “And what about economy?” — the model should understand that “economy” is still about refund policies, not start a brand-new search from scratch.
Technically, this can be done in different ways. A simple approach is to concatenate recent turns of the conversation and feed them together into the retriever and LLM. More advanced methods use summarized memory: the system distills the key points of earlier exchanges into a compact form, so it can carry long conversations without running into token limits. Some systems even use vector memory, where past queries and answers are embedded and stored, making it possible to recall relevant context on demand.

The result is a smoother, more natural experience. Users feel like they’re talking to a system that truly remembers, understands, and adapts, instead of one that resets after every question.
In Stack AI, conversational memory can be enabled directly through the Memory setting. Once switched on, you can choose between different strategies depending on how you want past interactions to be stored and recalled:
Sliding Window keeps track of the last few exchanges, passing them forward as context. This is useful for short conversations where only the most recent turns matter.
Sliding Window with Input goes a step further, retaining both the conversation history and the user’s latest input, so the system has a richer picture of the dialogue as it unfolds.
Vector Database stores previous interactions as embeddings, which allows the system to recall information across longer conversations or even sessions. This makes it possible for the AI system to “remember” details over time, not just in the immediate context window.

Wrapping Up
Advanced RAG can sound intimidating — hybrid search, reranking layers, multi-query decomposition… But in practice, Stack AI abstracts away much of the complexity, giving you these capabilities in a few clicks.
Combining different techniques like semantic retrieval, metadata filters, reranking, query rewriting, multi-query answering, citations, and memory, you can deliver AI systems that are more accurate, trustworthy, and user-friendly — without needing to fine-tune models or build infrastructure from scratch.

Ana Rojo-Echeburúa
Growth at StackAI
Mathematician turned AI consultant and educator. Passionate about helping businesses and individuals use data, cloud, and AI to solve real-world problems.






