If you’ve ever tried to pick “the best LLM,” you’ve probably realized pretty quickly that question doesn’t really have one answer.
Different models are good at different things. Some handle structured data beautifully. Others are great at reasoning or summarizing complex text.
So instead of asking yourself what the best model is, we recommend considering which models perform best for each type of task.
In this article, you'll find our leaderboard of the top LLMs for key real-world use cases we see across industries.
How We Built This Leaderboard
We gathered benchmark data and performance comparisons from multiple trusted sources and grouped results by task. For this article, we focused on eight tasks that represent the core of most enterprise AI workflows:
Document data extraction
Web research
Knowledge base search
Document review
Data classification
Legal review
Medical analysis
Financial analysis

For each one, we are break down which models dominate, what they’re good at, and what to watch for when picking the right fit.
The Leaderboards
1. Document Data Extraction
Pulling unstructured data from PDFs, invoices, or contracts is more than reading text. It's also about understanding format at a high level. The latest benchmarks highlight which models handle this best, combining precision, layout understanding, and reliable output formatting.
Rank | Model | Key strengths and justification |
1 | Gemini Flash 2.0 | Near-perfect OCR accuracy, scalable, cost-efficient |
2 | Claude 3.7 Sonnet | Multimodal, extremely strong contextual extraction, reliable on variable docs |
3 | GPT-4 Vision | Excellent for mixed-format/vision and text extraction, developer friendly |
4 | DeepSeek-VL2 | Top-tier OCR and context support, outperforming older OCR on varied layouts |
5 | GLM-4.5V/GLM-4.6 | Robust accuracy, broad multilingual, efficient on enterprise volumes |
6 | Qwen2.5-VL-72B-Instruct | High score in recent extraction competitions, architectural versatility |
7 | GPT-OSS-120B | Open-source, tunable, strong across unstructured data formats |
8 | Amazon Textract | For transactional, high-volume doc extraction at enterprise scale |
9 | DeepSeek-R1 | Shows strong balance of text/image extraction performance |
10 | Mistral-Small-3.2-24B | New entrant, high reliability on receipts/bills, cost-effective |
Gemini Flash 2.0 consistently ranks as the most accurate and cost-efficient option for both text and image-based extraction. It delivers near-perfect results on diverse business documents and even outperforms traditional OCR when it comes to scalability and flexibility.
Claude 3.7 Sonnet and GPT-4 Vision stand out for handling contextual, complex, and variable-format documents. Perfect when you need the model to understand structure, intent, and meaning rather than just pull fields.
On the open-source side, DeepSeek, the GLM series, Qwen, GPT-OSS, and Mistral have all shown strong performance across developer leaderboards and tool round-ups, especially for teams needing flexible, customizable options.
Amazon Textract remains the go-to for embedded LLM and OCR workflows in regulated environments, thanks to its native AWS integration and enterprise reliability.
Benchmarks show LLMs now surpassing OCR systems in real-world, irregular layouts and faster development timelines, though OCR still holds an advantage for strictly fixed templates.
The ranking reflects how each model performs across key dimensions: cost-efficiency, scalability, flexibility in prompt design, real-world extraction accuracy, multimodal (text + image) support, and ease of integration into enterprise systems. Models with multimodal capabilities — those that can actually see the document’s structure and layout — consistently outperform text-only models for this type of task.
2. Web Research
Web search encompasses browsing, summarizing, and reasoning across multiple sources in real time. It’s not only about retrieving links but also about understanding context, filtering noise, and producing concise, reliable insights from live information.
The best-performing LLMs in this space combine retrieval-augmented generation with up-to-date browsing capabilities, which lets them pull verified data, compare perspectives, and generate grounded summaries in seconds.
Rank | Model | Key strengths and justification |
1 | Perplexity AI | Top accuracy, live web integration, real-time cited answers, user favorite |
2 | Brave AI Search | Accurate and privacy-focused AI answers blended with classic search results |
3 | ChatGPT (with browsing) | Powerful natural language, links, context retention, robust web extraction |
4 | Microsoft Bing Copilot | Real-time web data, solid integration in Edge, supports citations, summaries |
5 | Google Gemini 2.5 AI | Fast, up-to-date, top speed (600+ tokens/s), high context and search fusion |
6 | Claude 3.7 Sonnet | Factually strong, detailed answers, safe, accurate (esp. for research) |
7 | DeepSeek (Comet) | Large context, advanced for technical/web research, real-time response |
8 | Arc Search | Multimodal, agent features, handles context and automation |
9 | You.com | Customizable search, "AI quick answers", strong privacy, good for devs |
10 | Kagi | Fast, accurate answers, customizable sources, high-quality results |
Perplexity AI takes the top spot for its ability to turn live web data into concise, citation-backed answers which makes it perfect for research, due diligence, and business intelligence. It consistently ranks above competitors for factual accuracy and offers a Pro Search mode for deeper, multi-layered exploration.
Brave AI Search is great for combining strong privacy with precise, trustworthy results. Its hybrid approach — blending traditional search results with AI-generated summaries — has been rated by reviewers as more useful and credible than Google or Bing’s AI assistants.
ChatGPT with Browsing remains a leader in conversational quality. It handles long-form reasoning, follows context across turns, and provides summarized, cited responses. Benchmarks highlight high user satisfaction and reliability, even if real-time updates can sometimes lag behind Perplexity or Gemini.
Microsoft Bing Copilot and Google Gemini 2.5 AI dominate speed and freshness benchmarks. Gemini leads for fast, structured outputs, while Bing Copilot is praised for clear, cited answers that combine traditional search with generative reasoning.
Claude 3.7, DeepSeek, Arc Search, You.com, and Kagi also make the leaderboard for their blend of conversational fluency, real-time or near-real-time browsing, and unique strengths from developer configurability to privacy-first search.
The ranking reflects a balance of factors: accuracy, live web accessibility, citation quality, speed, context retention, customization, and privacy. These scores are drawn from the latest benchmark reports, independent reviews, and side-by-side performance tests across leading AI search platforms.
For web research, models that integrate live browsing or retrieval systems consistently deliver more reliable, up-to-date answers than static LLMs limited to pre-trained data.
3. Knowledge Base Search
If you think of internal FAQs, policy documents, or enterprise wikis, these systems old very important information that’s often scattered, outdated, or buried deep in files. This is where retrieval-augmented generation (RAG) is incredibly useful.
Instead of relying solely on what they’ve been trained on, these models search, retrieve, and reason over your own knowledge sources — giving you grounded, source-backed answers in real time. The best ones handle large document stores, manage context efficiently, and maintain high factual accuracy even on niche topics.
Rank | Model | Key strengths and justification |
1 | DeepSeek-V3 | Superior context window, MoE efficiency, robust semantic search, RAG pipelines |
2 | GPT-5 | Top-tier semantic search, RAG, question answering, high enterprise adoption |
3 | Claude 3.7 Sonnet | Reliable, extremely accurate, stable long-context answers |
4 | Gemini 2.5 Pro | Advanced retrieval, hybrid neural and symbolic, rapid multi-modal KB integration |
5 | Qwen 3 | High multilingual support and document retrieval, fast context switching |
6 | Llama 3.3 70B | Open source, leading in fine-tuning and RAG, strong performance on open corpora |
7 | Mistral Large 2 | High reliability, open-source leadership for KB RAG tasks, custom pipeline support |
8 | Falcon 180B | Exceptionally performant for conversational Q&A and dynamic document access |
9 | Grok 5 (xAI) | Leader for organization-wide search, fast doc indexation, rich interactivity |
10 | PaLM 2 (Google) | Enterprise-grade, custom knowledge graphs, excels at factual queries |
DeepSeek-V3 leads this category thanks to its massive 128K+ context window, mixture-of-experts design, and proven accuracy in retrieval-augmented generation and semantic search pipelines. Benchmarks also highlight its growing enterprise adoption and reliability in large-scale deployments.
GPT-5, Claude 3.7, and Gemini 2.5 Pro follow closely behind, excelling in context retention, answer precision, and smooth integration across both commercial and open-source RAG frameworks. GPT-5 remains the most widely implemented in complex enterprise knowledge base systems.
On the open-source side, Qwen 3, Llama 3.3, Mistral Large 2, and Falcon 180B all deliver strong results when fine-tuned on custom KBs — with Llama and Mistral standing out for flexible, developer-friendly integration.
Grok 5 earns recognition for its speed and adaptability in dynamic knowledge environments, while PaLM 2 continues to be a solid choice for structured, factual, and well-curated internal datasets.
These rankings reflect a combination of factors:context window size, semantic search precision, RAG accuracy, retrieval speed, scalability, and real-world adoption across both open-source and enterprise setups. The evaluations draw from the latest benchmark reports, technical reviews, and industry leaderboards focused on practical, task-level performance.
4. Document Review
Document review combines extraction, summarization, and reasoning. This is essential for audit, compliance, and legal workflows. The goal here is to read documents, to interpret them but also to identify key clauses, highlight findings, and spot inconsistencies or missing information.
The strongest LLMs in this space handle long-context reasoning, multi-document comparison, and structured analysis, helping teams cut hours of manual review down to minutes without losing accuracy or nuance.
Rank | Model | Key strengths and justification |
1 | Qwen2.5-VL-72B-Instruct | State-of-the-art vision-language, deep context, best-in-class for charts/forms |
2 | GLM-4.5V | Efficient multimodal review, flexible “thinking mode,” SOTA on 41 benchmarks |
3 | DeepSeek-R1 | Massive model (671B), best for reasoning/deep review, 164K token window |
4 | Llama 4 Scout/Maverick | Native multimodal, scalable up to 10M tokens, high accuracy |
5 | OpenAI GPT-4 Turbo | Great multi-turn, extractive summarization, user-friendly |
6 | Claude 3 (Anthropic) | Detailed, accurate, compliance and regulatory focus |
7 | Gemini Pro (Google) | Native with Workspace, strong for scanned docs, multilingual |
8 | Mistral Large | High performance, open source, excels on legal/long documents |
9 | Llama 3.3 | Customizable, open source, fine-tuning friendly |
10 | Copilot (Microsoft) | Easy doc/cloud integration, strong for business formats |
Qwen2.5-VL-72B-Instruct leads this category with its multimodal strength — capable of analysing charts, tables, scanned images, and forms at enterprise scale. With a 131K context window and a high-parameter architecture, it consistently tops benchmarks for comprehensive document review, Q&A accuracy, and reliability across variable formats.
GLM-4.5V earns recognition for its “thinking mode” flexibility and efficient Mixture-of-Experts setup, striking a strong balance between speed, cost, and reasoning depth. It performs equally well on large-volume reviews and deep inference tasks that require logical analysis.
DeepSeek-R1 is a top pick for organizations handling extremely long or complex documents. Its 164K token context window and reinforcement-trained reasoning capabilities make it ideal for high-complexity compliance and audit pipelines.
Llama 4, GPT-4 Turbo, Claude 3, and Mistral Large appear consistently across major leaderboards for their well-rounded mix of extraction, summarization, multimodality, and easy integration into existing systems.
Gemini Pro stands out in multilingual and Google Workspace environments, while Copilot and open Llama variants remain popular among teams prioritizing flexibility, fine-tuning, or open-cloud deployment.
This ranking reflects performance across several dimensions — multimodal document benchmarking, context length, reasoning capability, and accuracy on complex or highly structured documents. It also considers cost-to-context efficiency, drawn from the latest enterprise-focused evaluations and 2025 benchmarking reports.
When it comes to document review, models built for long-context understanding and multi-step reasoning consistently deliver the most reliable results.
5. Data Classification
From sorting support tickets to tagging research papers or routing customer queries, classification tasks rely on speed, precision, and consistency. These models need to understand subtle differences in intent and context. Not just label text, but do it accurately and at scale.
The best-performing LLMs in this space combine strong embeddings, efficient fine-tuning, and low latency, making them ideal for real-time automation and large-volume processing.
Rank | Model | Key strengths and justification |
1 | GLM 4.6 | 200K context, outperforming DeepSeek; agentic & coding tasks, SOTA on benchmarks |
2 | Qwen3-235B-Instruct-2507 | 1M+ token context, top in reasoning/classification, multilingual excellence |
3 | DeepSeek-V3.2-Exp | Sparse attention, high-classification accuracy, efficient compute |
4 | DeepSeek-R1-0528 | Upgrades for logic/math, long context, AIME 2025: 87.5% in analytical/class tasks |
5 | GPT-OSS-120B | Open-weight, chain-of-thought, configurable, strong all-around |
6 | Apriel-1.5-15B-Thinker | Multimodal (text and image), high reasoning single-GPU performer |
7 | Kimi-K2-Instruct-0905 | 256K context, tool-augmented, agentic workflow specialty |
8 | Llama-3.3-Nemotron-Super-49B-v1.5 | RAG, tool-augmented, balanced reasoning, long-context |
9 | Mistral-Small-3.2-24B-Instruct-2506 | Reliable, compact, low error rates, WildBench v2/Arena Hard v2 gains |
10 | Falcon 180B | Open-source and optimized for analytics, high throughput |
GLM 4.6 tops this category performing particularly well on both classification accuracy and agentic workflow tasks. It delivers significantly higher benchmark scores and a broader context range than previous versions, outperforming key competitors such as DeepSeek, Qwen, and GPT-OSS.
Qwen3-235B-Instruct-2507 raises the bar for multilingual and long-context classification, surpassing GPT-4o and Claude Opus 4 (non-thinking mode) across several public leaderboards and real-world enterprise benchmarks.
DeepSeek models continue to lead in efficiency on sparse attention and analytical reasoning tasks, with the R1-0528 update showing major gains on AIME and other large-scale classification benchmarks.
GPT-OSS-120B and Apriel-1.5-15B-Thinker deliver open-weight flexibility with strong multimodal reasoning, while Kimi-K2 specialises in handling long-form and complex workflow classification.
Llama 3.3 Nemotron, Mistral Small, and Falcon 180B are regulars across both open-source and enterprise leaderboards, praised for their low error rates, toolkit compatibility, and ease of deployment in production systems.
These rankings are based on key factors such as classification accuracy across major benchmarks (AIME, WildBench v2, Arena Hard v2), context window size, reasoning capability for analytical tasks, multilingual range, and how well each model integrates with agentic or coding workflows. The insights come from a mix of technical reviews, benchmark reports, and open-source evaluations published this year.
6. Legal Review
Legal text is dense, formal, and often contains edge cases. This task tests a model’s ability to interpret nuance, maintain context across lengthy clauses, and stay compliant with domain-specific terminology and reasoning standards.
The best-performing LLMs for legal review combine long-context understanding, structured reasoning, and the ability to summarize or extract legal meaning without losing accuracy. They’re built to handle contracts, case law, and policy documents where precision isn’t optional, it’s essential.
Rank | Model | Key strengths and justification |
1 | DeepSeek-R1 | Largest 164K context window, elite reasoning and multi-document legal analysis |
2 | GPT-5 | Top accuracy (84.6%) on LegalBench, strong multi-step reasoning |
3 | Gemini 2.5 Pro | High accuracy (83.6%), fast latency, AI thought processing in legal workflows |
4 | Grok 4 | Strong legal performance (83.4%), effective workflow automation |
5 | Claude 3.7 Sonnet | Reliable legal reasoning, excellent compliance and formatting adherence |
6 | Qwen3-235B-A22B | Multilingual, dual-mode reasoning, suited for contract analysis |
7 | o3 | Balanced speed and accuracy, solid for procedural and contract review |
8 | GPT-4.1 | Good accuracy (81.9%), reliable for structured legal document generation |
9 | Llama 3.1 405B | Open-source option, competitive legal performance with data privacy benefits |
10 | Claude Opus 4.1 | Stable in format compliance, good for legal report generation |
DeepSeek-R1 leads this space with its massive 164K-token capacity and reinforcement-learned reasoning, which makes it great for complex contract analysis, multi-party agreements, and compliance reviews that demand long-context interpretation and logical precision.
GPT-5 ranks highest on the LegalBench leaderboard with an accuracy score of 84.6%. It’s particularly strong in multi-step legal reasoning, a must for tasks involving layered arguments, precedent analysis, and nuanced interpretation.
Gemini 2.5 Pro and Grok 4 both deliver impressive latency and accuracy, performing exceptionally well in legal AI agent workflows focused on document review, research, and compliance verification at speed.
Claude 3.7 Sonnet stands out for its structured, regulation-ready output. Its consistent formatting and reliable reasoning make it a favourite for generating legal summaries, case reports, and draft filings.
Other strong performers including Qwen3-235B, o3, GPT-4.1, Llama 3.1, and earlier Claude versions offer trade-offs between multilingual coverage, response speed, openness, and integration flexibility depending on the deployment needs.
These rankings draw from widely adopted LegalBench accuracy tests and complementary evaluations on multi-step reasoning, latency, cost efficiency, formatting reliability, and real-world workflow integration. The results reflect just how specialised legal AI has become: precision, compliance, and reasoning depth now define top-tier performance in this domain.
7. Medical Analysis
Healthcare data is high-stakes and full of technical language so there’s little room for error. In this field, correctness, interpretability, and trustworthiness are everything.
The strongest LLMs for medical analysis are trained or aligned with biomedical datasets and clinical notes, which giving them the ability to summarise, reason, and extract insights without distorting meaning. These models support diagnostic analysis, literature review, and medical coding, grounding every answer in verified information.
Rank | Model | Key strengths and justification |
1 | DeepSeek-R1 | Massive 671B parameters, 164K context window, reinforcement learning for clinical reasoning |
2 | OpenAI GPT-OSS-120B | Excellent clinical reasoning capabilities, health benchmark leader, efficient large-scale deployment |
3 | GLM-4.5V | Advanced vision-language with 3D spatial reasoning, multimodal medical imaging analysis |
4 | OpenAI GPT-OSS-20B | Lightweight, accessible healthcare AI, optimized for resource-constrained settings |
5 | Stanford MedGPT | Research model optimized for medical Q&A and patient communication |
6 | PaLM 2 Health | Enterprise-grade medical knowledge, custom knowledge graphs, factual precision |
7 | BioGPT+ | Specialized biomedical domain, excels on PubMedQA and medical literature summarization |
8 | Gemini 2.5 Pro Health | Fast inference, multimodal medical datasets support, good clinical utility |
9 | Apriel-1.5-15B-Thinker | Multimodal reasoning, capable of interpreting complex clinical charts and scanned images |
10 | Llama-Med | Open source, fine-tuned for healthcare Q&A and diagnostic support |
DeepSeek-R1 leads this category with its massive context window and reinforcement-trained reasoning, which enables deep multi-document clinical analysis and strong diagnostic accuracy. It’s particularly effective in complex case reviews where interpretability and precision are critical.
OpenAI GPT-OSS-120B ranks highly for clinical reasoning accuracy and scalability, which makes it a strong fit for enterprise healthcare systems that need secure, large-scale deployment.
GLM-4.5V stands out for its multimodal capabilities which combines text and vision understanding for medical imaging tasks like radiology and pathology. Its 3D spatial reasoning adds a layer of reliability that most text-only models can’t match.
OpenAI GPT-OSS-20B, Stanford MedGPT, PaLM 2 Health, and BioGPT+ all perform exceptionally well on medical Q&A, clinical summarisation, and biomedical literature review benchmarks, proving their value in specialised research and diagnostic workflows.
Gemini 2.5 Pro Health, Apriel Thinker, and Llama-Med round out the leaderboard, offering strong multimodal performance and flexible integration for healthcare applications that prioritise openness and adaptability.
These rankings are informed by performance on clinical reasoning benchmarks, multimodal medical imaging analysis, context length, reinforcement learning improvements, and cost-to-performance ratios. All key factors for healthcare deployment. They also take into account open-source accessibility, which remains a growing priority for research institutions and medical tech teams.
Models trained or fine-tuned on biomedical datasets consistently lead the field, setting the standard for accuracy and reliability in medical AI.
8. Financial Analysis
When you’re analysing market trends, risk profiles, or company valuations, models need more than language understanding. They need quantitative reasoning and contextual awareness. Financial data is dense, time-sensitive, and often unstructured, so accuracy and consistency are non-negotiable.
The strongest LLMs in this category combine advanced reasoning with numerical precision, handling everything from sentiment analysis and forecasting to report generation and compliance documentation. They’re built to interpret data the way an analyst would: logically, transparently, and grounded in evidence.
Rank | Model | Key strengths and justification |
1 | DeepSeek-R1 | 671B parameters, MoE architecture, exceptional quantitative finance, risk modeling |
2 | Qwen3-235B-A22B | Dual-mode reasoning, strong multi-step financial task performance |
3 | QwQ-32B | Cost-effective medium-sized model with strong reasoning and financial problem-solving |
4 | GPT-5 | Highest accuracy on FinanceReasoning benchmark with complex multi-step tasks |
5 | Gemini 2.5 Pro | Fast inference, excellent accuracy, well-integrated for finance applications |
6 | Claude Opus 4.1 | Strong performance with lighter token use, good efficiency-cost balance |
7 | FinGPT | Fine-tuned for finance sentiment, risk, and market forecasting |
8 | BloombergGPT | Specialized financial domain model for NLP tasks like news sentiment |
9 | InvestLM | Fine-tuned on LLaMA-65B for investment-specific financial understanding |
10 | FinLlama | Based on LLaMA 27B, fine-tuned for financial sentiment classification |
DeepSeek-R1 sets the gold standard for enterprise-level financial modelling, quantitative reasoning, and risk assessment. Its 671B parameters and Mixture-of-Experts architecture allow it to handle complex, multi-document finance workflows with precision and scale.
Qwen3-235B-A22B delivers dual-mode financial intelligence, equally strong in quantitative analysis and narrative interpretation. It’s praised for maintaining high accuracy while running on more efficient compute resources.
QwQ-32B offers robust reasoning at a lower computational cost, making it a practical choice for mid-sized financial firms and fintech startups that prioritize performance without the heavy infrastructure overhead.
GPT-5 and Gemini 2.5 Pro dominate the latest FinanceReasoning benchmarks, leading in accuracy, complexity handling, and adaptability across trading algorithms, valuation analysis, and forecasting use cases.
Claude Opus 4.1 earns points for efficiency offering solid analytical performance while keeping resource usage and cost under control, a strong fit for enterprise teams managing tighter budgets.
Domain-specific models like FinGPT, BloombergGPT, InvestLM, and FinLlama round out the leaderboard, which gives fine-tuned expertise in financial sentiment, market intelligence, and investment insights that blend domain precision with general-purpose LLM versatility.
These rankings reflect performance across key financial AI metrics: quantitative reasoning, multi-step logical inference, document understanding, and risk assessment accuracy. They also account for cost-performance efficiency and integration potential, based on leading financial market benchmarks.
Models like GPT-5, Claude Opus, and Gemini 2.5 Pro hold a clear advantage in reasoning-heavy financial tasks, particularly those that require multi-step analysis and precision under complex logic.
Choose the Best Model for Each Task in StackAI
In StackAI, you have access to one of the broadest selections of models and providers available, and you can use them across countless real-world tasks.
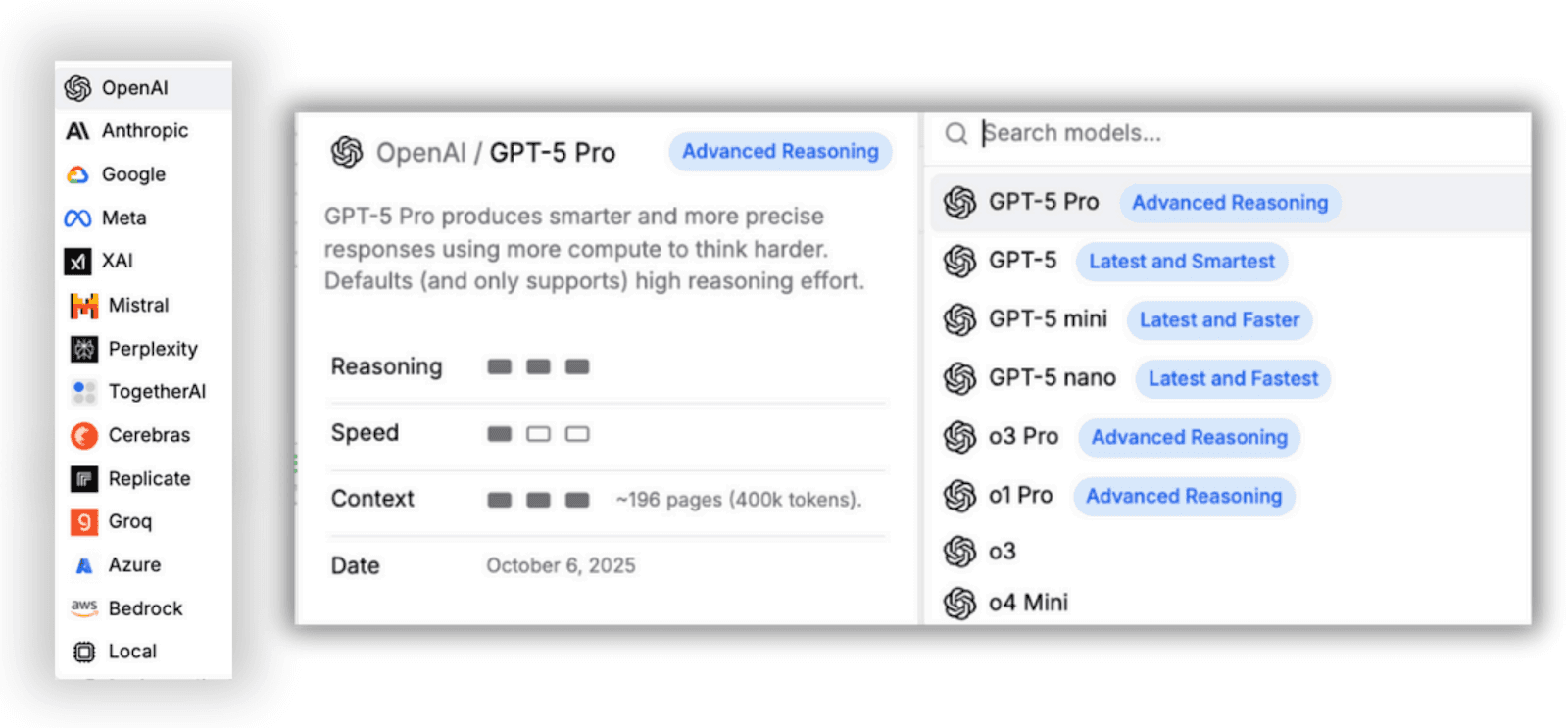
Each provider includes multiple models to choose from, so you’re not tied to a single ecosystem. What’s even better is that StackAI gives you built-in insights for each model. For instance, if you hover over OpenAI GPT-5 Pro, you’ll see how it performs across reasoning, speed, context size, and knowledge cut-off date. You can do the same for any other model.
With all this available directly in the platform and access to most of the top-performing models featured throughout this leaderboard, you can build applications that are both smarter and faster to deploy.
StackAI gives you everything you need to:
Create workflows from scratch or with pre-built templates
Filter templates by use case or industry
Explore models across multiple providers
Compare reasoning, speed, and context visually
Deploy and scale instantly
With StackAI, your choice of model becomes a strategic design decision, not a limitation. You have full visibility, flexibility, and control to build the best possible application for each task using the world’s leading models, all in one place.
Conclusion
The question “Which model is best?” doesn’t have a simple answer and it definitely isn’t solved by chasing the biggest or newest model. It’s about choosing the right one for the right task.
That’s why understanding how these models perform in different scenarios is such an advantage. It gives you the flexibility to experiment, adapt, and build workflows that actually make sense for what you’re trying to achieve.
Want to see LLMs in action on StackAI? Book a demo today.

Ana Rojo-Echeburúa
Growth at StackAI
Mathematician turned AI consultant and educator. Passionate about helping businesses and individuals use data, cloud, and AI to solve real-world problems.






